


Алексей Федянин
канд. тех. наук, инженер-геофизик, ВНИПИПТ (Москва)
Методика аппаратурной оценки параметров электронных
голосов, полученных методом транскоммуникации
канд. тех. наук, инженер-геофизик, ВНИПИПТ (Москва)
Методика аппаратурной оценки параметров электронных
голосов, полученных методом транскоммуникации
Основы существующей в настоящее время технологии записи феномена электронных голосов (ФЭГ) методом инструментальной транскоммуникации основаны на регистрации полезного сигнала в диапазоне звуковых частот от 20 Гц до 20 КГц с применением звукозаписывающих устройств типа генератора Кёнига. Источником сигнала гипотетически является некая энергоинформационная структура, при этом сигнал идентифицируется как похожий на голос человека и имеет характерную для него акустическую структуру и выраженную смысловую нагрузку. Подробно результаты исследований в области идентификации электронных голосов, фонетики и акустики приведены в работе Д. Гулла [1].
В настоящее время существует значительное количество записей ФЭГ различных языковых наречий, предоставленных в свободное использование. В качестве исходного материала для исследований были взяты электронные голоса русского и англо - американского наречий представленные Ассоциациями ИТК России и США, которые являются гарантами того, что данные не были фальсифицированы. Основной идеей исследований являлось определение корреляционных зависимостей между спектрами электронных голосов различных языковых наречий.
На основании ранее проведенных исследований установлено, что полезный сигнал ФЭГ характеризуется следующими особенностями:
1. Значительная фрагментированность, выраженная в отсутствии базовых частот, либо их завышении.
2. Аномальность в ритмике звука.
3. Узость диапазона звуковых частот;
4. Малые значения энергии в спектре звука.
Приведенные особенности показывают, что распознавание электронных голосов представляет значительную сложность и требует аппаратурного контроля при выявлении полезного сигнала в шумовом потоке, иногда намеренно создаваемом в звукозаписывающей аппаратуре.
Так же необходимо учитывать психологическую особенность человеческого мозга автоматически распознавать в звуковом потоке и интерпретировать звуки знакомые слушающему. Данный эффект зачастую приводит к ложному узнаванию в потоке ритмического шума слов родного наречия, или знакомых иностранных слов.
Выявление характеристических, базовых значений частот электронных голосов или маркирующего, характерного признака (т.е элемента постоянно присутствующего именно в электронном голосе) позволит автоматизировать процесс записи и распознавания и избежать непониманий по данному вопросу, которые существуют в настоящее время.
Таким образом, целью настоящих исследований являлось изучение и сравнение спектральных и акустических характеристик электронных голосов различных языковых наречий для выявления корреляции базовых параметров электронных голосов получаемых методом ИТК.
Для этого было необходимо решить следующие задачи:
1. Выбрать аппаратный комплекс позволяющий с высокой точностью проводить оценку спектральных и акустических характеристик как для звукового файла в целом, так и давать развернутую спектрограмму звукового цуга во времени.
2. Провести качественную оценку электронных голосов русского наречия, учитывая наличие в полезном сигнале как непосредственно вокоидов голоса, так и белого шума аппаратуры.
3. Составить характеристики электронного голоса, белого шума и голоса человека в виде типовых графиков спектра для каждого из вариантов.
4. Сравнить типовые графики спектра электронного голоса, голоса человека и белого шума с результатами итальянских исследователей.
Для решения первой задачи нами был выбран компьютер на базе процессора Pentiunm-IV с операционной системой Windows XP. Данная аппаратура общедоступна в отличии от оборудования L. Kersta [2] или сонографов, и позволяет проверить результаты исследований сторонним инициативным группам. Для обработки данных использовался специализированный пакет программ SpectraLAB компании Sound Technology, USA. Справа внизу показан анализ разборчивости речи, основанный на семи полосах частот.
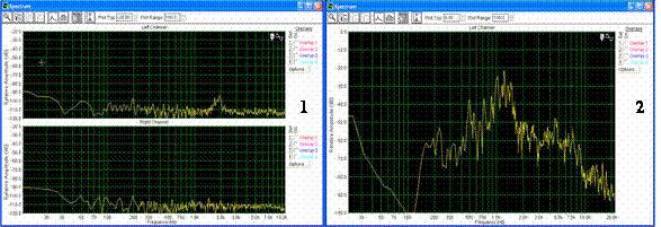
Рис.1. Графики спектра шума (1) и голоса человека русскоязычного наречия (2).
На рис.1. представлены спектры акустических комплексных сигналов голоса человека и белого шума. Как видно из графиков спектр человеческого голоса имеет значительно более сильный спектр и содержит большее число гармоник. Графики спектров построены в логарифмическом масштабе.
Сравнивая полученные нами результаты с результатами итальянских исследователей рис.2 (см. [1]), можно говорить о корреляции данных, достаточной, для инженерных расчетов. Общий вид спектров, при некотором допущении, остается принципиально идентичным.
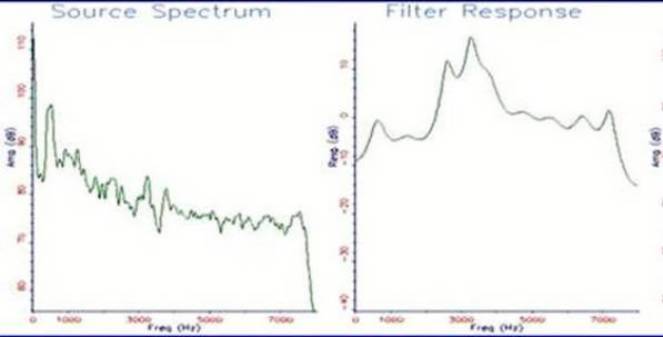
Рис.2. Графики спектра шума (а) и голоса человека (б) по Д.Гулла.
Таким образом, в результате сравнения исходных характеристик обычного человеческого голоса и «белого» шума, при различной аппаратуре и исходных данных, результаты спектрального сравнения базовых характеристик для итальянского и русскоязычного голосовых наречий совпадают в значительной степени.
Стоит отдельно уточнить, что в работе не учитывается национальные форманты голоса, за основу брались только базовые характеристики присущие человеческому голосу. Для оценки электронных голосов с сайта Российской Ассоциацией ИТК (http://www.rait.airclima.ru) были взяты файлы с различимым информационным содержанием, позволяющим однозначно интерпретировать услышанное.
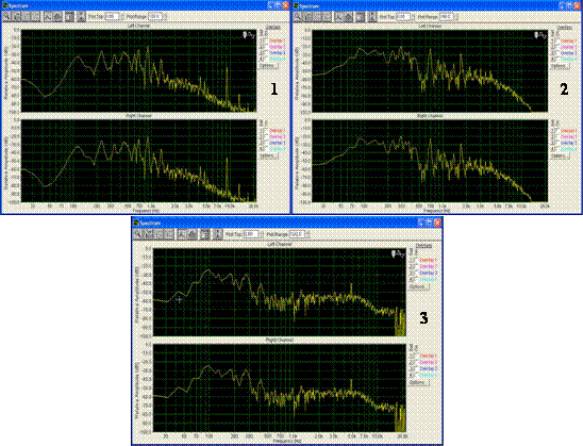
Рис.3. Графики спектров электронных голосов русскоязычного наречия. Названия файлов содержат информацию о сообщении электронного голоса : 1- привет с небес; 2 - мы бессмертны; 3 - ангелы хранители знают о тебе.
Как видно из графиков, форманты электронных голосов значительно отличаются от голоса человека, они не имеют четко выраженной базовой частоты, характеризуются неравномерностью распределения энергии в частотном спектре, четко выражен сдвиг формант речевого спектра в область частот не характерных для нормального человеческого голоса (рис.3.).
Данные характерные особенности так же были зафиксированы итальянскими исследователями [1], что по нашему мнению, позволяет говорить о том, что несмотря на значительную удаленность и не согласованность в проведении эксперимента результаты получены не предвзято, исходные данные не были сфабрикованы или сгенерированы с помощью специализированных программ.
Данные исследования могут быть так же апробированы инициативными группами ИТК других языковых групп. Эти исследования могут произвести значительный научный эффект в области доказательства универсальности феномена электронных голосов.
Еще более четко сдвиг базовых частот между обычным человеческим голосом и электронным голосом ИТК виден в трехмерной диаграмме спектра, отражающей изменение частот во времени рис.4.
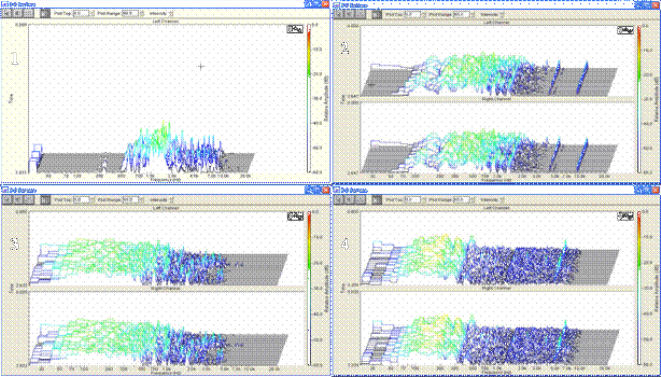
Рис. 4. Графики спектров электронных голосов русскоязычного наречия. Названия файлов содержат информацию о сообщении электронного голоса :1- голос человека,
2 – «привет с небес»; 3 – «мы бессмертны»; 4 – «ангелы хранители знают о тебе»
2 – «привет с небес»; 3 – «мы бессмертны»; 4 – «ангелы хранители знают о тебе»
Также проведена оценка спектра электронного голоса англо - американского наречия . Файл на рис. 5 содержит информацию «I survived», http://www.atransc.org ).
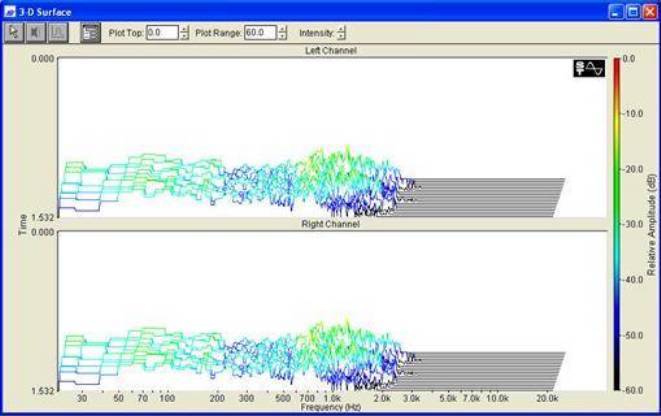
Рис.5. Графики спектра электронного голоса англо - американского наречия.
Видно, что характерный для ФЭГ рисунок спектра частот, имеет место в различных языковых наречиях, что может быть использовано для выявления полезного сигнала в непрерывном режиме работы станции ИТК. Очевидно, что малая контрастность сигнала потребует более сложного алгоритма для выявления начала и конца фразы. Поэтому, нами рекомендуется использовать, для более однозначной идентификации, поиск по базовой частоте гласных звуков человеческой речи, но в модуляции характерной для ФЭГ.
В данной связи была проведена оценка уровня постмодуляции сигнала самого устройства, с целью уточнения, что характерные для ФЭГ графики спектров электронных голосов не являются производными транформации сигнала самого психофона.
Установлено, что входящий полезный сигнал с микрофона, который проходит все звенья записывающего устройства и подвергается всем предусмотренным в психофоне постмодуляционным изменениям, практически не подвергается трансформации.
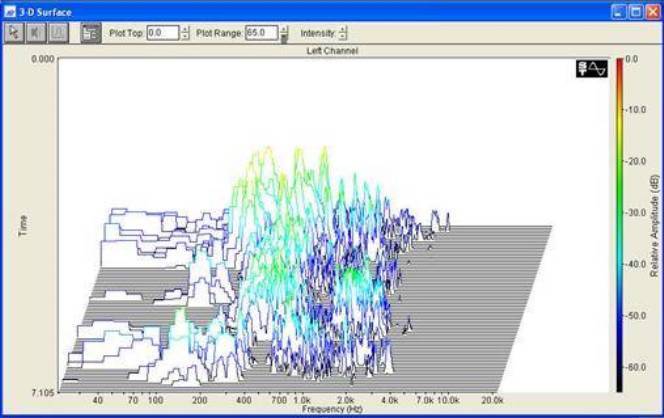
Рис.6. Графики спектров голоса человека и электронного голоса при диалоге.
На графике (рис.6) видны спектры голоса человека и следующий за ним ответ электронного голоса. Различие между спектрами голосов видно по базовым характеристикам и сопутствующим гармоникам. Голос человека имеет сильный выраженный спектр и гармоники в пределах частот от 200 до 700 Гц с амплитудой порядка -10 dB, а также отчетливые стабильные значения низкочастотного спектра. Электронный голос имеет амплитуду порядка -20 dB и включения с несколькими базовыми интервалами частот 80 -150 КГц, 250 - 450Гц, 1.5 - 2.5 КГц, так же отчетливо видны изменения низкочастотного спектра (10 - 70 Гц).
Проведенные исследования говорят о том, что полученные графики спектров ФЭГ являются уникальными и постоянны для многих языковых наречий, а также не являются причиной постмодуляционных изменений в звукозаписывающей аппаратуре типа психофон.
Также необходимо отметить, что рассмотренные примеры идентифицируются как содержащие смысловую нагрузку, однако рассмотрение информационной части ФЭГ в данной работе не проводилось.
Таким образом, на основании проведенных исследований можно сделать следующие выводы:
1. Феномен электронных голосов регистрируется различными аппаратными комплексами, позволяющими с высокой точностью проводить оценку спектральных и акустических характеристик, давать развернутую спектрограмму во времени.
2. Корреляция данных полученных итальянскими и русскими группами ИТК говорит о непредвзятом отношении к эксперименту, отсутствии сфабрикованных или сгенерированных с помощью специализированных программ исходных данных.
3. Базовые характеристики спектра электронных голосов в малой степени зависят от национальной форманты.
4. Существующая корреляция характеристик полезного сигнала электронных голосов различных языковых наречий обуславливают возможность создания универсальной системы выявления базовых акустических параметров присущих только электронным голосам ИТК. Для идентификации голоса рекомендуется использовать, поиск по базовой частоте гласных звуков человеческой речи, но в модуляции характерной для ФЭГ.
5. Форманты электронных голосов значительно отличаются от голоса человека, они не имеют четко выраженной базовой частоты, характеризуются неравномерностью распределения энергии в частотном спектре, четко выражен сдвиг формант речевого спектра в область частот не характерных для нормального человеческого голоса.
6. Показана возможность создание пакета специализированных программ позволяющих выделить полезную составляющую сигнала из белого шума в непрерывном режиме работе станции ИТК на основе анализа характерных для ФЭГ акустических частот.
Список использованных материалов
1. Д. Гулла. Компьютерный анализ гипотетических «паранормальных голосов», их обнаружение и идентификация. http://www.rait.airclima.ru/voice_analysis.htm
2. Хильдегард Шефер. Мост между мирами.
http://www.rait.airclima.ru/books/Bridge_between_worlds.doc
3. Материалы Российской ассоциации инструментальной транскоммуникации (РАИТ)
3. Материалы Российской ассоциации инструментальной транскоммуникации (РАИТ)