


Даниэль Гулла
инженер-электронщик, специалист в области акустики и спектрографии, эксперт в области парапсихологии и паранормальных явлений, сотрудник лаборатории биопсихокибернетических исследований (Болона, Италия)
Компьютерный анализ гипотетических "паранормальных
голосов", их обнаружение и идентификация
1. Прослушивание звуковых записей: между психоакустической перцепцией и электроакустическим анализом
инженер-электронщик, специалист в области акустики и спектрографии, эксперт в области парапсихологии и паранормальных явлений, сотрудник лаборатории биопсихокибернетических исследований (Болона, Италия)
Компьютерный анализ гипотетических "паранормальных
голосов", их обнаружение и идентификация
1. Прослушивание звуковых записей: между психоакустической перцепцией и электроакустическим анализом
Прослушивание записей «феномена электронных голосов»,полученых в результате экспериментов по «инструментальной транскоммуникации», требует от экспериментаторов необычно напряженного внимания.Чтобы понять откуда берутся эти «голоса» и правильно их оценивать, им нужно иметь хотя бы общее понятие о работе психоакустической системы человека, включая фундаментальные принципы фонетики и акустики. Эта статья адресована увлекающимся «паранормальными голосами» и содержит резонные аргументы относительно сложностей прослушивания и идентификации акустического материала, служащего основой для биопсихокибернетических исследований (кстати термин «биопсихокибернетика» здесь употребляется как альтернатива устаревшим «парапсихология» и «паранормальное»).
1.1. Шаг первый. Материал прослушивают один или несколько человек
На этом этапе следует принять во внимание разницу в слуховых способностях каждого слушающего.Особенности слухового аппарата и мозговых зон, ответственных за распознавание слуховых образов индивидуальны. На пути от барабанной перепонки до заполненной особой жидкостью улитки, звук проходит через многочисленные проводящие структуры. Толстый жгут нервов соединяют улитку со слуховыми центрами мозга.
Широко распространенное мнение, будто человек слышит в интервале 20Гц - 20 КГц, кажется необоснованным. Последние акустические исследования свидетельствуют,что некоторые люди слышат даже ультразвук, если излучатель приложен непосредственно к костям головы, когда нет передачи звуковых волн по воздуху. Человек, таким образом, может слышать звуки от 20 до 70 КГц, в точности так же, как он воспринимает обычные высокочастотные тоны по воздуху. Кажется,что у некоторых людей где-то в слуховом аппарате есть особый спектральный анализатор, способный разделять звук на гармоники, подобно тому, как работает преобразование Фурье. Эта особенность позволяет ставить человека в один ряд с животными, имеющими особо утонченный слух, хотя и заниженные звукоанализаторские способности. Для примера можно взять хотя бы возможность некоторых лиц различать малейшие ньюансы партитуры каждого инструмента в сложнейших симфонических произведениях.
1.2. Шаг второй. Определение языкового наречия
Кроме чисто слухового восприятия услышаных звуков, необходимо провести их электроакустический анализ. Не секрет, что ухо склонно интерпретировать некоторые звуки, резонирующие с нашими слуховыми стереотипами, как часть языковой речи. Это особенно касается случаев, когда источником слов служит не конкретное лицо, а различные шумы, в которых пытаются отыскать компонент речи. Другими словами говоря, это уже область «психолингвистики». Обратите внимание на рис 1.
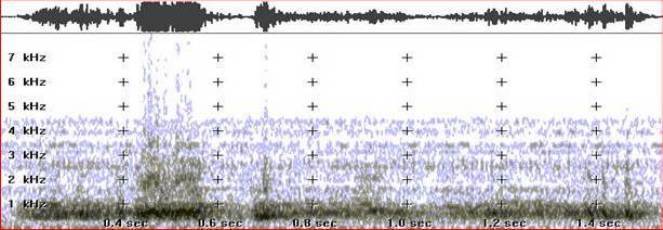
Рис. 1 - Ритмические шумы, в которых можно предполагать наличие речевого компонента.
Возможность услышать в этом шуме что - либо зачастую зависит от личных способностей слушающего. Диапазон раличий здесь очень велик и зависит главным образом от уровня практических навыков оператора.Некоторые люди способны налету схватывать мелкие звуковые нюансы, моментально их дифференцировать и интерпретировать, сравнивая в уме со своими личными звуковыми стереотипами. Когда, например, кто - либо учит иностранный, он поначалу неизбежно будет склонен слышать в шумах слова именно этого языка, но с течением времени он начнет слушать «более широко» и сравнивать услышанное со всеми известными ему формами звучания того или иного изречения. Таким образом, если кто-либо хочет хорошо освоить правильное произношение и понимание чужих слов, он должен тренировать свой слух прослушиванием их звучания. Именно личные особенности слуха обьясняют разницу в способностях слышания «паранормальных голосов» у новичков и систематически занимающихся практикой «инструментальной транскоммуникации». Большинство звуков, которые мы слышим, включая и речь, образуются многочисленными волнами, состоящими из разнообразных асинхронных компонентов. Любой реальный звук может рассматриваться как алгебраическая сумма большого количества синусоидальных колебаний, каждый из которых имеет свою частоту и амплитуду. Если нам известны эти компоненты и их характеристики, мы можем создать графический образ спектра даного звука. Из периодических сигналов,путем математического анализа, можно выделить несколько «базовых» частот. Эти частоты обычно представляют низкочастотные высокоамплитудные синусоиды,а все остальные, кратные от базовых - их гармоники. Спектр акустического комплексного сигнала, например, человеческого голоса (см. рис. 3), непостоянен - это так называемый «дискретный» спектр. Спектр синусоиды одной частоты (например от генератора) представляет прямую линию, в то время как в шуме очень много разных частот, следовательно много и разных спектральных линий,их настолько много,что линии сливаясь,образуют на рисунке один сплошной массив (см. рис. 2). Следовательно различие между разными аудиториями слушающих, может прежде всего базироваться на разнице прослушивания «периодических» и «непериодических» сигналов (с гармоническими и негармоническими спектрами). Эти разные сигналы мы обычно называем «звуками» и «шумом».
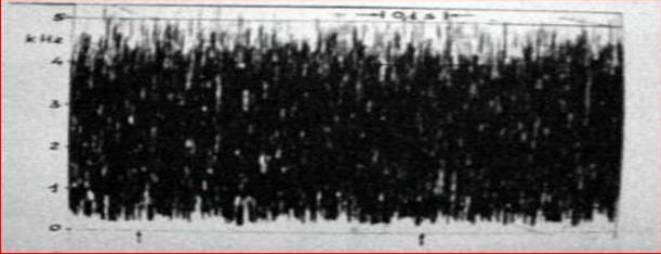
Рис. 2 - Спектр «белого» шума.
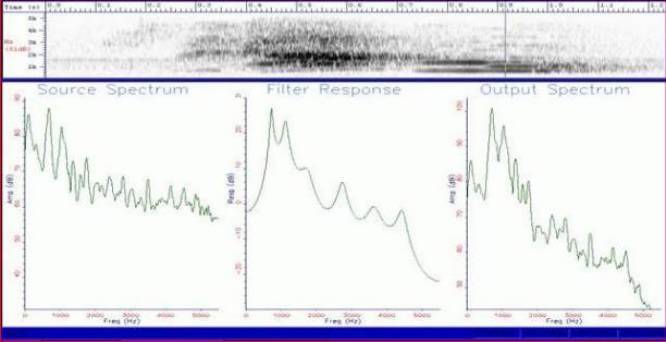
Рис. 3 - Спектр человеческого голоса (по Bersani - Trevisan). Голос наложеный на шум посредством респонс - фильтра. 1 - спектр шума, 2 - спектр голоса, 3 - то,что получилось в итоге.
Среди звуков речи выделяют так называемые «вокоиды» - звуки пения, представляющие собой простые тоны. Если же говорят о «контоидах» - имеют ввиду звуки с примесью шумов. В реальной речи звуки не произносятся по буквам, они звучат единой цепочкой, хотя между отдельными словами и есть небольшие паузы.
1.3. Шаг третий. Что определяет речь как человеческую
Как уже было сказано, сложные звуки, составляющие человеческого голоса (впрочем как и музыкальных инструментов) состоят из набора простых синусоидальных колебаний. Самая низкая синусоидальная частота называется «базовой», а все прочие - ее «гармониками», которые могут быть четными и нечетными. Реальные характеристики человеческого голоса, его интенсивность, тембр и разборчивость зависят от совокупности свойств гармоник,его составляющих. В детском высоком голосе, например, совсем немного гармоник, в типично женском - их побольше, из-за чего голос становится более сочным. Мужские низкие голоса еще более насыщены - в них гармоник больше всего. Личный тембр каждого голоса зависит от так называемых «формант». На пути от голосовых связок до выхода изо рта звуковые колебания встречают множество резонирующих структур, вследствие чего одни резонируют и рассыпаются на гармоники больше, чем другие. Вариантов того,что после этого получается бесчисленное множество и все в конечном итоге зависит от индивидуальных особенностей звукоформирующих путей каждого. Изучение формант имеет смысл, в частности, для понимания их роли в формировании тембра голоса. Человеческий звуковой аппарат, как устройство, наиболее развит и совершенен. Никакие другие звуковые устройства не способны так вариабельно менять свои звуковые характеристики. Конечно, кое на что способны и музыкальные инструменты, где путем незначительных регулировок удается достигнуть изменения звучания, не меняющего, однако основных его характеристик.
В противоположность инструментам,человек может произвольно изменять тембр голоса, напряжение голосовых связок и размеры резонирующих полостей. В реальной жизни для того, чтобы произнести слово, требуются многочисленные модификации легочно - губного тракта, скорость которых может достигать 50 - 60 раз в секунду. Это порождает беглость и нечеткость человеческого голоса, не свойственную другим источникам звука.
Практически звуковой тракт работает как эквалайзер, усиливающий только определенные частоты - «форманты». У взрослых развитая ротоглотка резонирует обычно на 500, 1500 и 2500 Гц. Это так называемые три базовых форманты, которые позволяют математически вычислить длину звукового тракта человека - около 17.5 см. Здесь не учтены, однако, индивидуальные особенности звукопродуцирующего субьекта.
Национальные значения формант голоса итальянцев несколько отличны, например, от французов и русских. Более того, форманты голоса самих итальянцев имеют отличия, зависящие от места жительства и разнообразия языкового диалекта. Более того, даже одни и те же гласные каждым голосом произносятся по - своему. Здесь имеет значение частотная высота первых двух формант, позволяющих определить,что же звучит «и», «е», «а», «о» или «у» (см. рис. 4).
Человеческий голос имеет множество характеристик и для занимающихся практикой «ИТК-паранормальных голосов» необходимо правильно различать и сравнивать их при прослушивании звуковых записей. Естественно, что на этом этапе нам важно представить количественные и качественные характеристики услышанного, полученные в результате реальных измерений. Некачественно проведенная запись рискует быть оставленной без анализа из - за опасности неправильной интерпретации. Более того, из - за некачественности мы можем потерять важные спектральные, морфологические и структурные составляющие, содержащие важную информацию.
1.4. Шаг четвертый. Обнаружение голосовых аномалий
Принимая во внимание основные характеристики человеческого голоса, мы можем определить номинальные отклонения от базовых составляющих и использовать это при анализе данных.Здесь уже необходимо привлечь специалистов по фонетике, изучающих речь и ее тональности. Используя так называемую технологию «стандарта фонетической транскрипции» и ее условные символы,они могут квалифицировано распознать язык исследуемой речи.

Рис. 4 - Значения первых двух формант (F1 и F2), соответствующих итальянским,
французким и английским гласным.
французким и английским гласным.
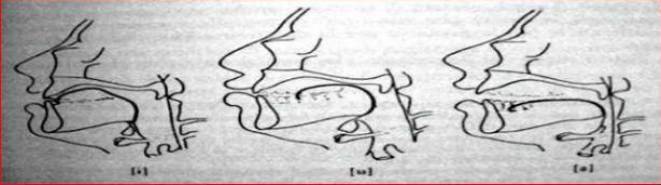
Рис. 5 - Примеры артикулярных позиций при произнесении трех итальянских гласных (слева направо: i, u, a).
2. Примеры анализа «потусторонних» голосов
На рисунках 6 и 7 представлен анализ магнитной записи голоса Gracula Religiosa, птицы, известной под названием Хилл Майна. Здесь мы работаем со словом «Ренато», которое по замыслу исследователей, птицу специально научили произносить утрированно. Аномальность, на которую я хочу обратить внимание будет более понятной, если вы посмотрите на рис. 8 и 9, где я, имитируя птицу, попытался произнести то же слово сам. На нижнем рисунке вы видите странную фигуру компьютерной реконструкции голосового тракта того, кто произнес это слово. Как видите, никак нельзя сказать,что это рисунок звуковых путей человека!
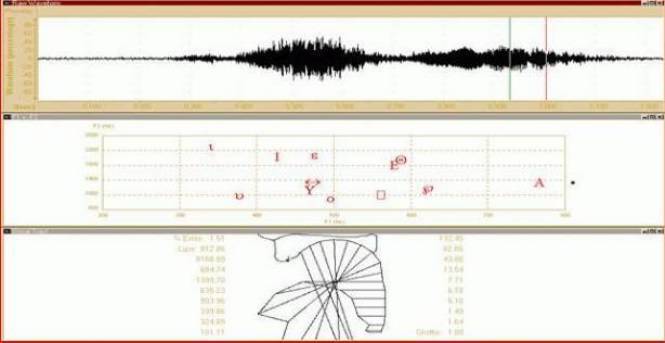
Рис. 6 - Голос птицы, пытающейся произнести слово «Ренато».
Мой голос, несмотря на неясность «О - У» произношения на диаграмме более похож на человеческий, а на виртуальном рисунке ротоглотки, почти не вызывает сомнений. Некто захочет спросить, а зачем нам, собственно, понадобился утрированный голос птицы? Ответ простой, в то же время и не очень. Отчасти мы можем найти его в физиологии слухового анализатора и особенностях его восприятия мелодичных звуков с вплетенными в них элементами речи. В опыте компютер выдал заключение, что анализируемый звук из-за нарушения риторики не вполне соответствует слову «Ренато» и только мелодия звучания была воспринята и откорректирована нашим мозгом так, что мы услышали «Ренато».
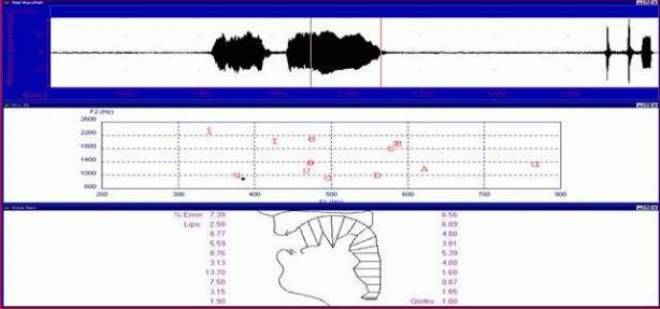
Рис. 8 - А это мой голос, когда утрируя птицу, я попытался произнести слово «Ренато».
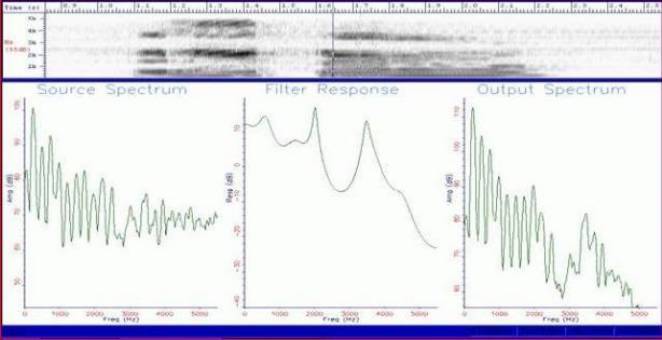
Рис. 9 - Общая спектрограмма и спектр гласной “O”, произнесенные мною.
3. Некоторые примеры анализа «паранормальных голосов»
На рис.10 мы видим спектрограмму предположительно аномального голоса,записаного на магнитофон в условиях полной тишины Михаэлем Диникастро (Менеджер парапсихологических исследований при лаборатории биопсихоэнергетики). Голос вроде бы произносит слово «Гэзу» («Иисус»).
На спектрограмме, представляющей структуры формант, почти не видно базовой частоты и какой-либо вибрации голоса,характерной для человеческой речи. В этом вы можете убедиться сами. Отчасти мы можем объяснить это явление тем,что слово произнесено почти шепотом.
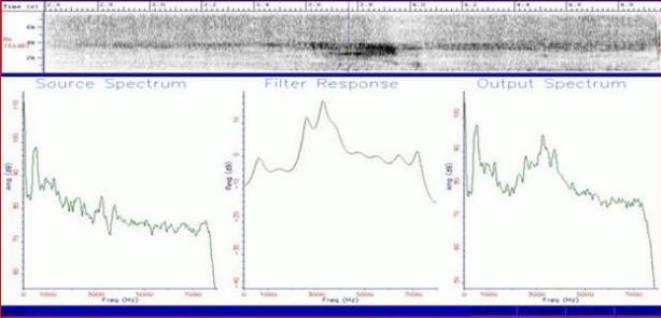
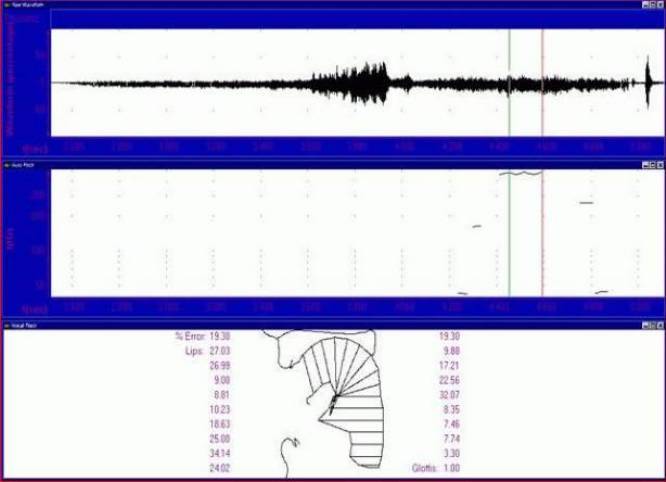
Рис. 10, 11 - Микрофонный голос предположительно паранормального происхождения
кажется, произносит слово «Гезу» («Иисус»).
Центральная часть осциллограммы, соответствующая звуку «Ге» вообще не содержит базовой частоты F0 и потому соответствующая ей модель горла не прорисована. На участке звука «У», выделеном двумя вертикальными линиями, говорящий тракт обычный без каких - либо аномалий. Звукообразующие структуры также не обнаруживают чего - либо необычного. Глотка же, надгортанник и гортань несколько удлинены и подвинуты вперед.
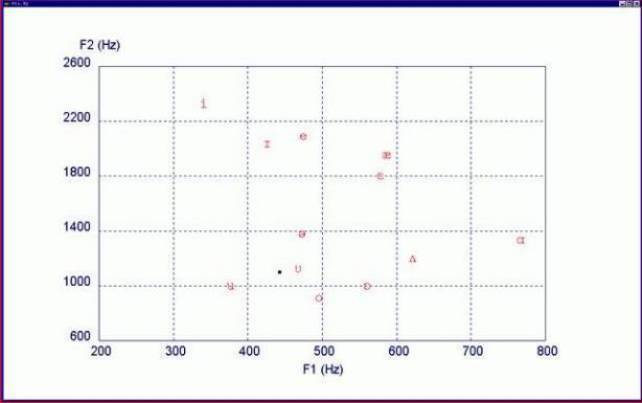
Рис. 12 - Таблица формант (F1 и F2) слова «Гезу».
Рис.12 демонстрирует значения первых двух формант (F1 и F2) относительно гласного «У» в слове «Гезу». Черными точками отмечены усредненные позиции формант и тип рабочей фонемы. В даном случае звук соответствует слегка открытому «у», произнесенному как нечто среднее между «у» и «о». В англо - американском фонетическом словаре такой звук более походит на аналогичный в слове «hood». В итальянском же языке конечное «у» зачастую краткое, из чего можно сделать вывод,что трактовка слова Михаэлем Диникастро заслуживает доверия. Начиная с предыдущей гласной «е», форманты обрываются и голосовые вибрации не определяются, компьютер не выводит значения формант, однако если вы внимательно посмотрите на спектрограмму, то обнаружите наличие следов звука в диапазоне 617 и 2588Гц, соответствующих закрыто произнесенному звуку «е».
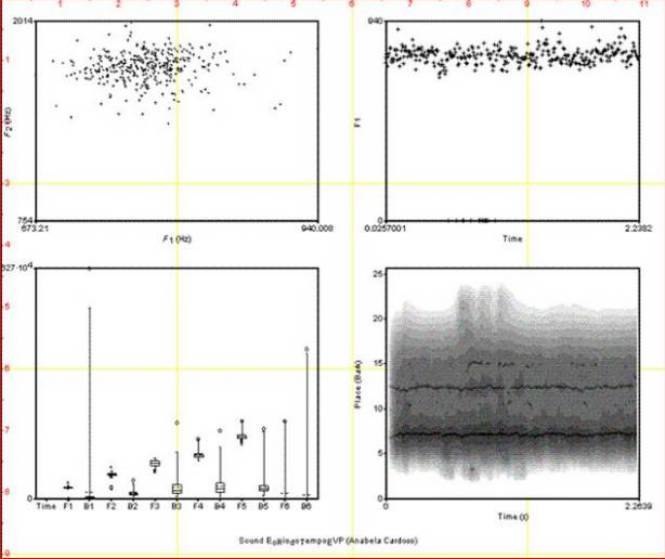
Рис. 13 - Паранормальный голос, записаный Анабелой Кардозо.
Голос произносит «Е рио до темпо».
Голос произносит «Е рио до темпо».
На рис.13 представлены данные параметрического анализа паранормального голоса, зафиксированного Анабелой Кардозо. Этот анализ демонстрирует богатство формант и динамичность голоса. Во многих местах графика можно обнаружить наличие трех узкополосных формант и стабильность их частотно - временных отношений. На спектрограмме определяется также некоторая примесь шумов, обусловленая наличием псевдогармонических частот. Неоднократное прослушивание этих звуков подтвердило богатство интонаций фразы, истолкованной как «Е рио до темпо» (река времени). Анализ частот гласных звуков представляет определенную трудность, а многообразие вариантов гортанных вибраций не позволяют воссоздать на карте формант рисунок звукового тракта,точно отражающий фонетическую позицию. Для практических целей грубо можно принять утверждение,что поскольку голос образуется в сегментах звуковового тракта и выходит наружу как бы рывками, не затрудняя понимание смысла, слушающий фактически воспринимает «кванты звукового шума» - термин,более распространен в техническом вещании. Даже если мы имеем дело с большими сигналами, процедура электронного распознавания никак не будет излишней,поскольку каждая особь имеет свои частотные характеристики голоса. Имей мы больше спектральных данных, мы смогли бы «выловить» больше аномальных голосов в интервале между местом их возникновения и способом образования. На сегодняшнее время они классифицируются так:
11 мест возникновения, разделеных на три категории:
1 – место происхождения частоты F2;
2 - место происхождения частоты F3;
3 - частотные шумы.
16 звукопроводящих мест, разделеных на 6 категорий:
a - форма и скорость звукопроведения;
b - место происхождения частоты F1;
c - источники шума;
d - усилители шума;
e - лабильность звукопроводящих сред и путей,определяющие характеристики звуковых консонант.
4. Что можно сказать,кратко подытожив имеющиеся данные
1. Паранормальные голоса не имеют базовых частот, а если они и есть,то сильно фрагментированные.
2. Скудость тембра,обусловленая дефектами частотного состава паранормального голоса.
3. Структура формант часто прерывается шумовыми наплывами несинусоидального характера.
4. Ненормально пропорционирована вторая форманта с усилением высших гармоник, скудость интонаций и фрагментированный спектр.
5. Необычность спектрального состава, значительная завышенность значений базовых частот.
6. Необычность распределения звуковой энергии в спектре,что можно объяснить узостью диапазона звуковых частот в паранормальных голосах, что не дает возможности манипулировать мелодией речи.
7. Аномальности в ритмике звука,обнаруженные аутокорелляционным анализом.
8. Неравномерность распределения энергии в частотном спектре голосов.
9. Аномальность звуковой вариабельности,не позволяющей правильно составить акустическую карту голоса.
10. Аномальности в потоке речи: то она растянута,то сильно ускорена.
11. Частичная или полная элизия консонант.
12. Неправильная гармония речи.
5. Сравнительные оценки в распознавании голосов
Метод распознавания голосов на основе технологии сравнения с уже известными (записаными телефонными или разговорными) берет свое начало еще с 1937 года,со времени известного процесса по делу о похищении сына первого покорителя Атлантики Лидберга. До этого времени по даному вопросу проводились лишь единичные опыты. Позже, в 1962 году, используя так называемое «улучшенное телефонное оборудование» метод усовершенствовал L. Kersta. Его технология заключается в спектральном анализе фонограмм,записаных на сонографе фирмы Кэй Элеметрикс (http://www.kayelemetrics.com) плюс компютерный метод с составлением карты подобий голосов (см. пример ниже).
Гипотеза математического распознавания голоса базировалась на особенностях речевого аппарата человека (размер гортани, ротовой полости, языка и т.д.), которые, несмотря на «унифицированность» произношения слов, делают это произношение в каждом случае индивидуальным. Именно эти индивидуальные особенности речевого аппарата приводят к тому,что одни звуки в речи резонируют лучше других,особенно при произношении гласных. На спектрограмме это выглядит как сгустки энергии звука на одних частотах и ослабление ее на других, т.е.мы регистрируем уже знакомые нам «форманты». Каждый гласный звук имеет свои типичные, уже изученные форманты, но формула этих формант у каждого человека индивидуальна. Как и для гласных, уже изучены форманты согласных звуков,таких как «М», «Н», «Р». Их поток вместе с гласными формирует мелодию речи, дающей нам еще несколько индивидуальных параметров. Данные характеристики присущи естественной, т.е.не «синтезированной компьютером» речи. На спектрограмме мелодия речи определяется волнами амплитудной низкочастотной модуляции, называемой «тональностью» и обозначаемой как F0. Используя Cepstrum аналогичные характеристики можно получить на графике тренда F0 даже в случаях искусственно фальсифицированного голоса (певучей речи, например). Но как бы не фальсифицировался голос, он всегда сохраняет индивидуально присущие ему математические характеристики. Принимая во внимание все вышеизложенное, учитывая, что паранормальные голоса звучат неестественно на фоне шумов, компьютерный анализ речи является незаменимым для сравнения голоса виртуального говорящего с зарегистрированным голосом уже известного, но умершего человека. Из - за скудости базы данных прижизненных голосов, эксперты нередко затрудняются в формулировке заключений. Как уже говорилось, речевой спектр паранормальных голосов очень скудный, нередко испорчен различными шумами. В сообщениях, полученых в разное время и различными исследователями, на различном оборудовании спектры голоса одних и тех же предполагаемых «потусторонних» лиц были весьма различны, в их составе обнаруживались нетипичные человеческой речи частоты - «флуктуации» не только в разных записях,но и на фонограммах, выполненых в одно и то же время. Эти необычные флуктуации легко могут ввести исследователей в заблуждение при идентификации и даже вызвать сбой компьютерных программ анализа, настроенных на алгоритмы распознавания нормальной речи. В таком случае дело приходится брать на ручной контроль, привлекая математические процедуры и расчеты. Другими словами, самостоятельно анализировать спектрограмму. Если запись голоса не произведена на качественном оборудовании, в фонограмме всегда есть немалое количество ошибок.
Иногда случается удача, когда можно сравнить два одинаково звучащих слова, но такие моменты, увы, редки. Я поражаюсь, как много факторов, помимо действительно полезной информации, нужно принять во внимание исследователям голоса (многочисленные характеристики голоса + характеристики аппаратных шумов). Большое счастье для исследователя, если он имеет дубль записи, полученый по другому каналу и есть возможность сравнить характеристики совпадающих элементов (слов,например).
На практике, сравнительное распознавание речи в группах 154 человек дало ошибку в 4.4% и 928 чел – 2.8%,что может говорить о высокой достоверности метода.
Для анализа компьютеру достаточно участка фонограммы длительностью в 10 секунд, вне зависимости от содержания информации,поскольку характеристики произношения гласных и согласных в одном и том же голосе не меняются. На рисунках 14,15 и 16 представлена гистограмма сравнения паранормальных голосов с теми «живыми» голосами, что уже есть в базе данных.

Рис. 14 - Сравнение «загробного» и прижизненного голосов одного и того же лица (матричное сравнение).Синим - голос ди Жуана при жизни, красным - «посмертный» голос «Joao». Базовые частоты голоса F1, F2, F3 совпали в 42% точек сравнения, F4, F5 - 74%.
На рис 14 показана матрица формант паранормального голоса,полученая Анабелой Кардозо. Красными точками обозначены форманты паранормального голоса,назвавшегося «Joao». Синими - форманты прижизненного голоса того же лица. Предполагается,что именно он вышел на паранормальную связь.
К сожалению, на основании имеющихся данных (для сравнения взято всего лишь одно слово) нельзя с полной уверенностью сказать,что голос принадлежит именно ему. Заключение должно быть осторожным и мы можем лишь констатировать,что по параметрам эти два голоса совместимы,без значительной разницы (см. совпадения процентов выше). В другом примере идентификация производится на трехсекундном материале паранормального голоса, записаного в Гроссето (Италия) центром Марчелло Баччи.
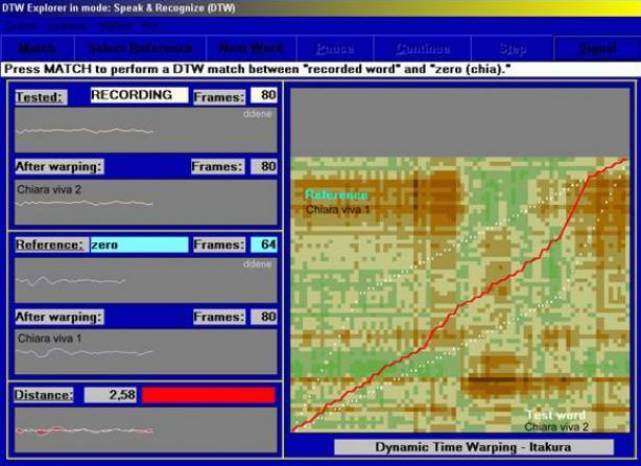
Рис.15 - Сравнение двух фонограмм одного и того же прижизненного голоса Чиары Лензи, полученных в различных ситуациях. Эвклидова дистанция голоса = 2.58.
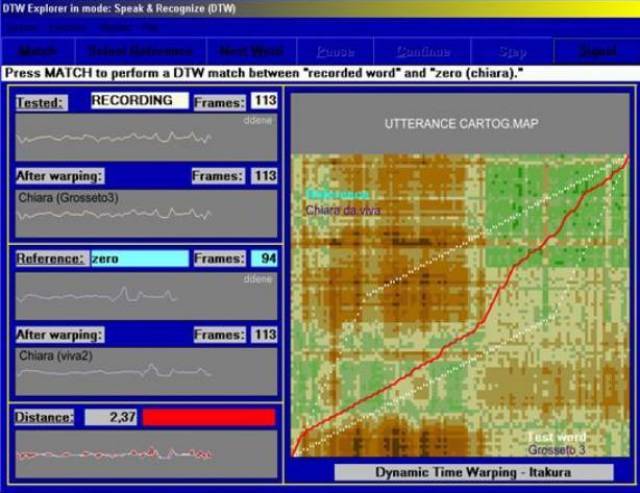
Рис.16 - Сравнение прижизненного и «посмертного» голосов Чиары Лензи, полученные в лаборатории Гроссето. Эвклидова дистанция 2.37, меньше предыдущей.
На рис. 15 сравнены прижизненные голоса девушки Чиары Лензи,записанные в двух различных ситуациях,где она произносит слова: «Ун басьоне а те чиара». Эвклидова дистанция (математическое выражение дистанции отклонений) прижизненного голоса = 2.58. Если мы измерим тот же показатель на фонограмме паранормального голоса, записаного в Гроссето, где отец умершей д-р Джузеппе Лензи подтвердил, что это голос именно его дочери, мы увидим что Эвклидова дистанция здесь значительно меньше прежде измеренной (см. рис. 16). В даном примере, в отличие от предыдущего, мы можем уверенно утверждать,что это речь одного и того же лица. Если бы это был криминальный случай или потребовалось опознать личность говорящего для каких - либо других целей, заключение экспертов звучало бы как «ВЫСОКАЯ СТЕПЕНЬ СОВМЕСТИМОСТИ ГОЛОСОВ»
6. Итоги
Бывает, что аномальные голоса определенны и распознаются относительно нетрудно. В других случаях приблизительность и двойственность звучания не позволяет их надежно идентифицировать. В таких случаях только практический навык решит, отнести ли услышаное к нормальным или паранормальным явлениям. Здесь,как мы видели на примере с «Gracula Religiosa» не обойтись без задействования инструментальных данных,дающих гораздо больше,чем обычный слух, объективной информации.
По моему мнению, здесь немалое значение имеет комплексный подход. Сигнал может вариироваться в широких пределах от чистого и легко анализируемого до зашумленого и не поддающегося обработке.
Мы надеемся, что изучение паранормальных голосов ИТК в лаборатории Болоны (http://www.laboratorio.too.it) в кооперации с французами и бразильцами положит более прочный фундамент для осмысления этого феномена. К сожалению официальная наука и парапсихология не уделяют даному направлению изысканий должного внимания.
Литература
Oskar Schindler (1974), Manuale di audiofono - logopedia, Omega, Torino.
F.Ferrero - A.Genre - L.J.Boe - M.Contini (1979), Nozioni di fonetica acustica, Omega, Torino.
Z.Muljacic (1969), Fonologia generale e fonologia della lingua italiana, Il Mulino, Bologna.
De Dominicis (1999), Fonologia comparata delle principali lingue europee moderne, Coop. Libr. Universitaria Edit. Bologna.
P.Gramming - J.Sundberg (1988), Spectrum factors relevant to phonetogram measurement, JASA 83, pagg. 2352-2360.
F.Alton Everest (1997), Manuale di acustica, Hoepli, Milano.
R.L.Klevans-R.D.Rodman (1997), Voice recognition, Artec House Inc.,Boston.
R.B.Randall (1987), Frequency Analysis, Bruel Kjaer
D.Gulla (2000), Voci paranormali e analisi di laboratorio, L’uomo e il Mistero/8, Edizioni Mediterranee, Roma.
D.Gulla (2000), Proposta di una metodologia di ricerca per l’analisi di presunti eventi acustici paranormali di origine fonetica, Atti del Convegno del Ce.S.A.P. (Dip. di Bioetica) Universita degli Studi di Bari 27/10/2000.
P.Presi (1988), Psicofonia e paranormalita elettroniche, in “Esperienze Paranormali”, AA.VV., Edizioni Mediterranee, Roma.
P.Presi (2000), Il paranormale in laboratorio: “voci psicofoniche”,”voci telefoniche” e ”voci dirette” a confronto, L’uomo e il Mistero/8, Edizioni Mediterranee, Roma.
D.Gulla. (2003), Riconoscimento ed identificazione tramite le impronte vocali, Relazione contenuta nel 2° Anno del Corso Multimediale di Biopsicocibernetica del Laboratorio di Bologna.
Перевод В.А.П.
25.09.2006