


Артем Михеев
канд. физ. - мат. наук, президент РАИТ (Санкт - Петербург)
Явление стохастического резонанса и его применение в инструментальной транскоммуникации
канд. физ. - мат. наук, президент РАИТ (Санкт - Петербург)
Явление стохастического резонанса и его применение в инструментальной транскоммуникации
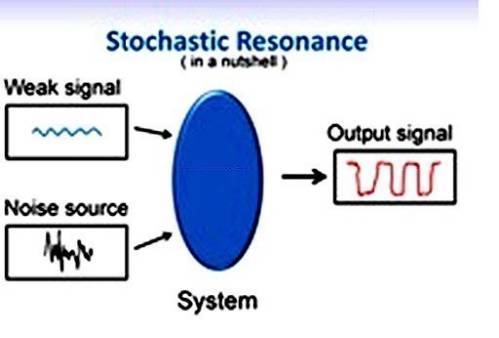
Если говорить вкратце, явление "стохастического резонанса" заключается в усилении слабого модулирующего сигнала при его взаимодействии с шумовым фоном. Как предполагает в своей книге исследователь феномена электронного голоса, инженер - радиоэлектронщик Ньютон Брага, этот эффект скорее всего лежит в основе записи так называемых микрофонных голосов ФЭГ.
По информации сайта membrana.ru, не так давно подобный же эффект использовался физиками из Принстонского университета для извлечения картинки, замаскированной в случайном шуме. ( http://www.membrana.ru/particle/3901)
В книге Хильдегард Шефер "Мост между мирами" (глава 27) описана процедура последовательной перезаписи (re-dubbing) полученных паранормальных изображений, изобретенная первопроходцем транскоммуникации Клаусом Шрайбером. При этом качество картинки не ухудшалось с увеличением количества шагов, как следовало бы ожидать с точки зрения здравого смысла, а наоборот, улучшалось.
В 2008 году нами совместно с моим коллегой, инженером - гидроакустиком Вадимом Свитневым, было открыто явление, которое было бы уместно назвать "СТОХАСТИЧЕСКИМ ФОНЕМНЫМ РЕЗОНАНСОМ". Именно оно, как я убежден, лежит в основе работоспособности мультитрекового метода, опробованного кроме нашей группы уже многими десятками экспериментаторов.
Описание его вариантов можно найти здесь (пункт 1.4)
Итак, попытаюсь кратко объяснить свою точку зрения на то, как именно это работает.
Для начала предлагаю каждому проделать простую вещь: сделать 15-20 - секундную запись внутреннего шума с обычной звуковой карты компьютера, без привлечения микрофона. Чтобы уровень был достаточен, можно выставить опцию усиления. Если Вы затем достаточно глубоко отфильтруете запись в Cool Edit, то почти наверняка сможете обнаружить там явное наличие голосов. Увы, уровень их громкости и разборчивости слишком слаб, так что по-настоящему вытащить их из-под шума - задача практически невыполнимая. Как мы видим, воздействие на звуковую карту может идти практически непрерывно. Можно сказать, что на стохастический сигнал налагается некая информационная "матрица" в виде слабой модуляции, лежащей глубоко под уровнем шума.
Теперь предположим, что мы добавили к этому шуму однородный речевой фон в виде речевой подложки: звуковых консервов или смеси радиотрансляций. Если наши партнеры "оттуда" сформируют свой, пусть изначально слабый и неслышимый сигнал строго определенным образом, то есть если он будет согласован со звучащей речевой подложкой по некоторым фазово - частотным характеристикам, то за счет резонанса в определенных местах они смогут усилить отдельные участки своего сигнала, или же наоборот, подавить отдельные фонемы подложки. При этом расход энергии с их стороны будет минимален.
Действительно, им не требуется формировать сигнал "с нуля", но лишь "играть в такт", эффективно подстроившись под то, что уже есть. Так происходит конверсия (преобразование) содержимого подложки. Если это воздействие идет целенаправленно, за те 4 итерации, которые идут в мультитрековом методе, их сигнал успевает приобрести достаточную амплитуду, чтобы быть более-менее прилично слышимым после фильтрации. Громкость и разборчивость этого сигнала зависит от того, насколько им удачно удается "подстроиться". А удается, должен признать, часто весьма неплохо (см. примеры результатов).