


Даниэль Гулла
инженер-электронщик, специалист в области акустики и спектрографии, эксперт в области парапсихологии и паранормальных явлений, сотрудник лаборатории биопсихокибернетических исследований (Болона, Италия)
Анализ паранормальных звуковых феноменов в программе "Скайп"
(с) перевод А.В. Михеев, 2013.
инженер-электронщик, специалист в области акустики и спектрографии, эксперт в области парапсихологии и паранормальных явлений, сотрудник лаборатории биопсихокибернетических исследований (Болона, Италия)
Анализ паранормальных звуковых феноменов в программе "Скайп"
(с) перевод А.В. Михеев, 2013.
Аннотация. В данной статье проводится анализ звукозаписи, предоставленной д-ром Адрианом Кляйном (Израиль), содержащей звуковые сигналы, напоминающие человеческую речь, возникшие во время беседы через коммуникационную систему "Скайп". Электроакустический анализ был выполнен при помощи нескольких программ. Он показал, что указанный звуковой сигнал более напоминает модулированный шум, чем вокальную артикуляцию человека. В частности, звук является модулированным в более широком и более высоком частотном диапазоне, с постоянным изменением частоты, сравнимым с тем, что имеет место при работе синтезатора.
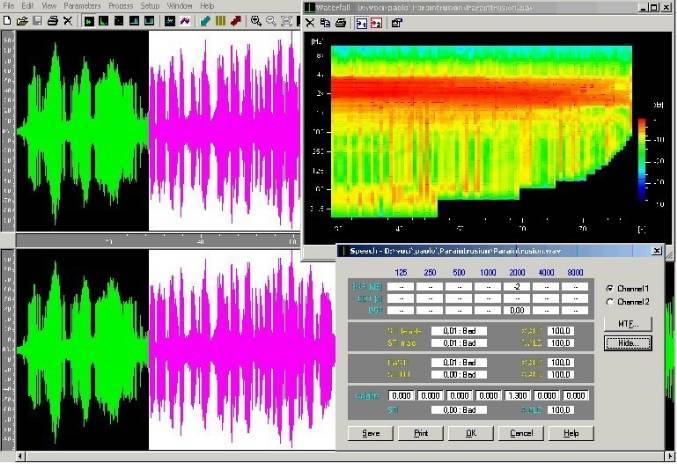
Рис. 1
Фиолетовая часть осциллограммы на рисунке 1 представляет из себя искомую помеху. В правом верхнем углу рисунка в виде цветовой диаграммы приведена амплитудно-частотная характеристика (АЧХ) сигнала. Справа внизу показан анализ разборчивости речи, основанный на семи полосах частот.
Согласно диаграмме, сигнал лежит в постоянной полосе, с максимумом амплитуды в диапазоне от 1 до 4 Кгц. За исключением изолированных пиков, низкочастотная составляющая сигнала практически отсутствует. Если принять сигнал за речевую артикуляцию, его разборчивость практически равна нулю (составляет 0.01 - Bad)
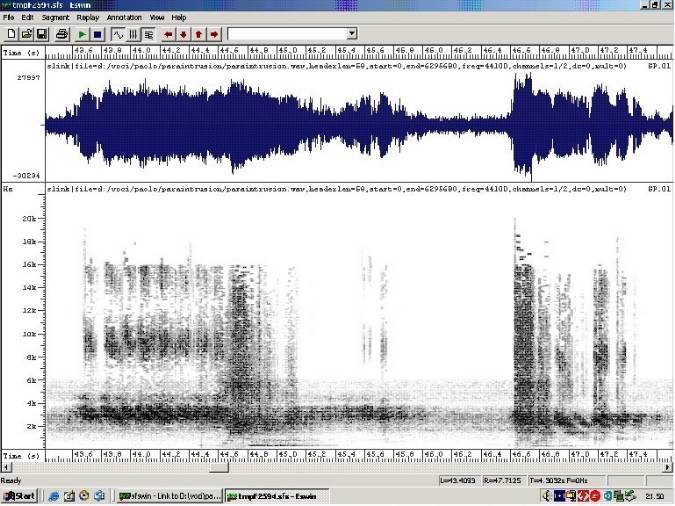
Рис. 2
Если расширить полосу до 20 КГц (предыдущая была 8 КГц), некоторые всплески энергии могут быть обнаружены от 8 до 12 КГц и от 14 до 16 КГц (рис. 2). Энергия носит волнообразный характер и ее тип сходен с тем, что производится сэмплером или электронным синтезатором.
Характеристики голосоподобного сигнала
Диапазон времени: с 53.061003 по 69.128389
Длительность: 16,067386 сек.
Высота тона (Pitch):
Медиана: 274,774 Гц
Средняя: 305,748 Гц
Стандартное отклонение: 113,124 Гц
Минимум: 137,250 Гц
Максимум: 499,675 Гц
Импульсы (Pulses):
Количество импульсов: 482
Количество периодов: 432
Средний период: 3.362400*10^(-3) сек.
Стандартное отклонение периода: 1.358713*10^(-3) сек.
Вокализация (Voicing):
Доля локально девокализированных фрагментов: 74,860% (1203/1607)
Количество голосовых перерывов: 27
Уровень голосовых перерывов: 84,930% (13,645969 секунд / 16,067386 секунд)
Джиттер (фазовое дрожание):
Джиттер (локальный): 6,854%
Джиттер (локальный, в абсолютном выражении): 230.451*10^(-6) сек.
Джиттер (rap): 3,613%
Джиттер (ppq5): 4,314%
Джиттер (DDP): 10,838%
Шиммер звуковой:
Шиммер (локальный): 15,891%
Шиммер (локальный, Дб): 1.380 дБ
Шиммер (apq3): 8,867%
Шиммер (apq5): 11,490%
Шиммер (apq11): 14,880%
Шиммер (ДВР): 26,601%
Гармоничность голосовых фрагментов:
Среднее автокорреляции: 0.598294
Среднее отношение шума к гармоникам: 0.713393
Среднее отношение гармоник к шуму: 1,809 дБ
Анализ показывает невозможность классифицировать образец как естественный голос, поскольку 74 процента от артикуляции звука не распознаются программой в качестве голоса. Кроме того, отношение сигнала к шуму, равное 1.8 Дб, не является приемлемым для точного анализа электроакустических параметров, подобных формантам, и вычисления коэффициентов линейного предсказания (Linear Prediction Coefficients - LPC) и кепстра.
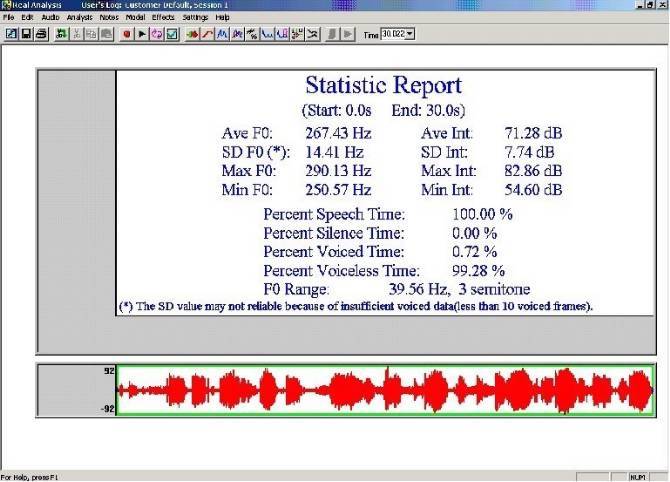
Рис. 3
На рисунке 3 показан статистический анализ присутствия частоты основного тона F0 для гласной (A). Соответствующие значения скорее стационарны, присутствие F0 весьма незначительно и фрагментировано, следовательно материал является недостаточным для лингвистического анализа.
С помощью программы "Dr. Speech", недавно приобретенной нашей лабораторией, было установлено, что только 0.72 % от F0 может считаться лежащим в границах параметров, присущих мужскому голосу. Осциллограмма, представленная на рисунке 3 внизу и окрашенная в красный цвет, демонстрирует недостаток F0. При обнаружении F0 диаграмма окрашивается в зеленый цвет.
На рисунке 4 анализируются короткие участки, распознанные как F0. Они характеризуются значительными вариациями тона, лежащими в промежутке от 1.5 до 7.6 мсек. Анализ высоты тона (pitch) демонстрирует на некоторых фрагментах значительные изменения во времени. Изменения высоты тона как величины, обратной фундаментальной частоте F0, представлены в миллисекундах на вертикальной оси слева.
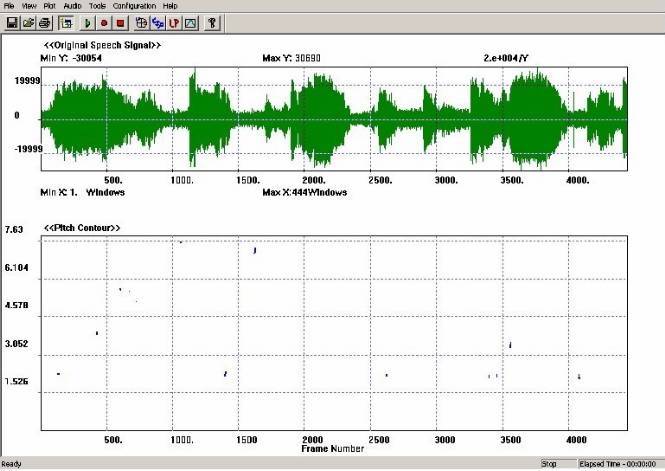
Рис. 4
Анализ возмущения гласных с использованием программы "Dr. Speech", привел к выводу о невозможности его полноценного выполнения из-за неопределенности и фрагментации F0. Еще одной причиной этой невозможности послужило смешение тональных компонент гласных с шумом вследствие определенного канала связи или внутренней природы сигнала (см. предупреждение на рис. 5). Анализ формант, показанный на рисунке 6, показывает таблицу рассеяния гласных IPA. Все гласные
находятся в передней губно-постальвеолярной и губно-небной области.
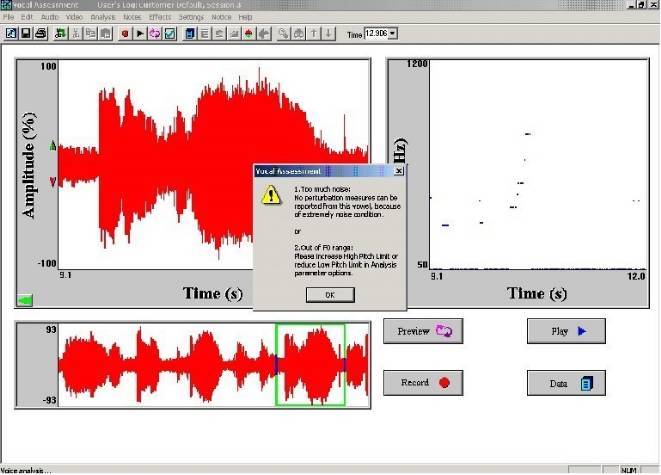
Рис. 5
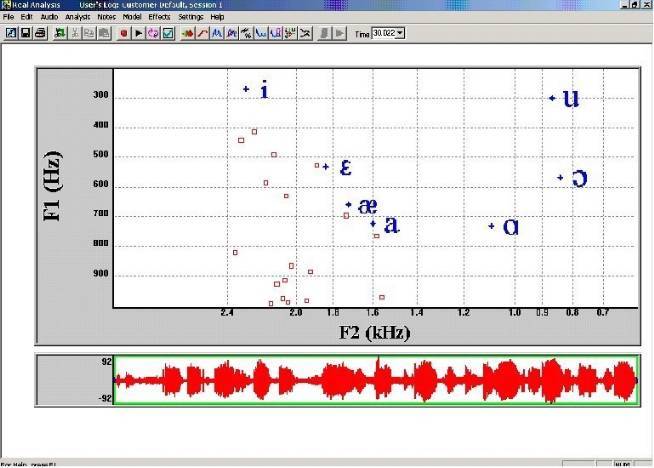
Рис. 6
Далее на рисунке 7 показан анализ, проведенный с использованием вейвлет модальности, где шум имеет паттерн в виде "малых волн". Это очень похоже на сигнал, обработанный вокальным синтезатором.
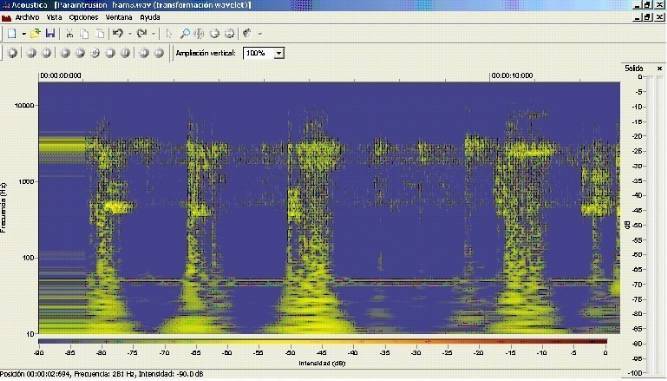
Рис. 7
Инструментальный анализ, выполненный с использованием систем обработки данных, доказывает только наличие характеристик, не присущих человеческому голосу, в том что касается частоты основного тона F0 и траекторий формант Fn. Присутствие сильного шума в полосах частот Fn вызывает неопределенность в распределении значений, затем возникают трудности с подбором специфических
алгоритмов, таких как кепстральный анализ, требующих определенной точности спектрального представления сигнала для того, чтобы определить характерный частотный диапазон для каждой выделенной фонемы.
Обнаруженные аномалии, такие как значения частоты основного тона F0 и формантная статистика, могут рассматриваться как внутренние особенности анализируемого сигнала или, учитывая сильные искажения спектра, подобные тем, что используются во многих процессорах акустических эффектов (синтезаторах), могут рассматриваться как сигналы искусственного происхождения.
Принимая во внимание невозможность выполнения аккуратного параметрического анализа, вопрос о том, может ли сигнал рассматриваться как синтезированный искусственным образом, или же являет собой проявление электронного голосового феномена (ЭГФ), остается открытым. К сожалению, я не располагаю паттернами с расширенными параметрами для анализа характеристик синтезированных сигналов. В любом случае, насколько я знаю, с помощью синтезатора возможно создать голосовые сигналы, более близкие к человеческой речи, чем те образцы, которые были рассмотрены в данном примере.